团队成员介绍
大娃
后端开发人员,主要工作为后端开发,文档撰写。
大娃的
二娃
PM,主要工作为项目进度把控,平日例会的记录,例会博客及部分其他博客的撰写。
二娃的
三娃
PM,主要工作为项目进度把控,用户需求分析,组织平日例会,各类博客的撰写。
三娃的
四娃
前端开发人员,主要工作为网页各项功能的实现,文档撰写。
四娃的
五娃
后端开发人员,主要工作为后端开发,文档撰写。
五娃的
六娃
测试,主要工作为测试前后端代码,发现bug交付给开发组。
六娃的
七弟
前端开发人员,主要工作为网页各项功能的实现,文档撰写。
七弟的
此外,团队博客中也有一篇关于团队成员的详细介绍(附成员美照),链接如下:
工程相关信息
1.用户定位
需求分析
如今deep learning大火,很多计算机人甚至其他专业的人都会向deep learning中跳,但从0到入门这一过程中着实面临着一些困难:
- 除了看教材以外,没有好的入门方法
- 教材中的概念比较抽象,不易弄懂
- 教材中的例子都是以代码形式的,并不直观
可见现有的学习途径对初学者并不是很友好。所以我们想搭建一个在线平台, 提供给用户可拖拽的编程方法,通过图形连接自动生成程序。用这种方式可以帮助没有接触过deep learning的人更快、更直观地理解基本原理,并做一些前期的简单练习,能够快速入门。
同时,我们还会为用户提供论坛形式的讨论平台,帮助用户在学习过程中遇到困难有求助渠道,提高用户之间的互动性及用户体验。
典型用户
我们设想的典型用户为有一定计算机基础、想要学习deep learning的人,且通过教材、博客的学习感觉有些生涩难懂、吃力。
预期功能及用户数量
预期功能有:
- 拖拽搭建模型,并生成相应模型代码
- 搭建论坛,方便用户发帖提问、讨论(与之相印的要实现注册/登陆功能)
用户数量:
- 访问量上:预计突破1000
- 生成模型数量上:预计突破400
- 注册人数上:预计突破200
2.产品现状
Alpha版本支持的功能主要为搭建模型——设置参数——生成代码,具体页面如下:
搭建模型

设置参数
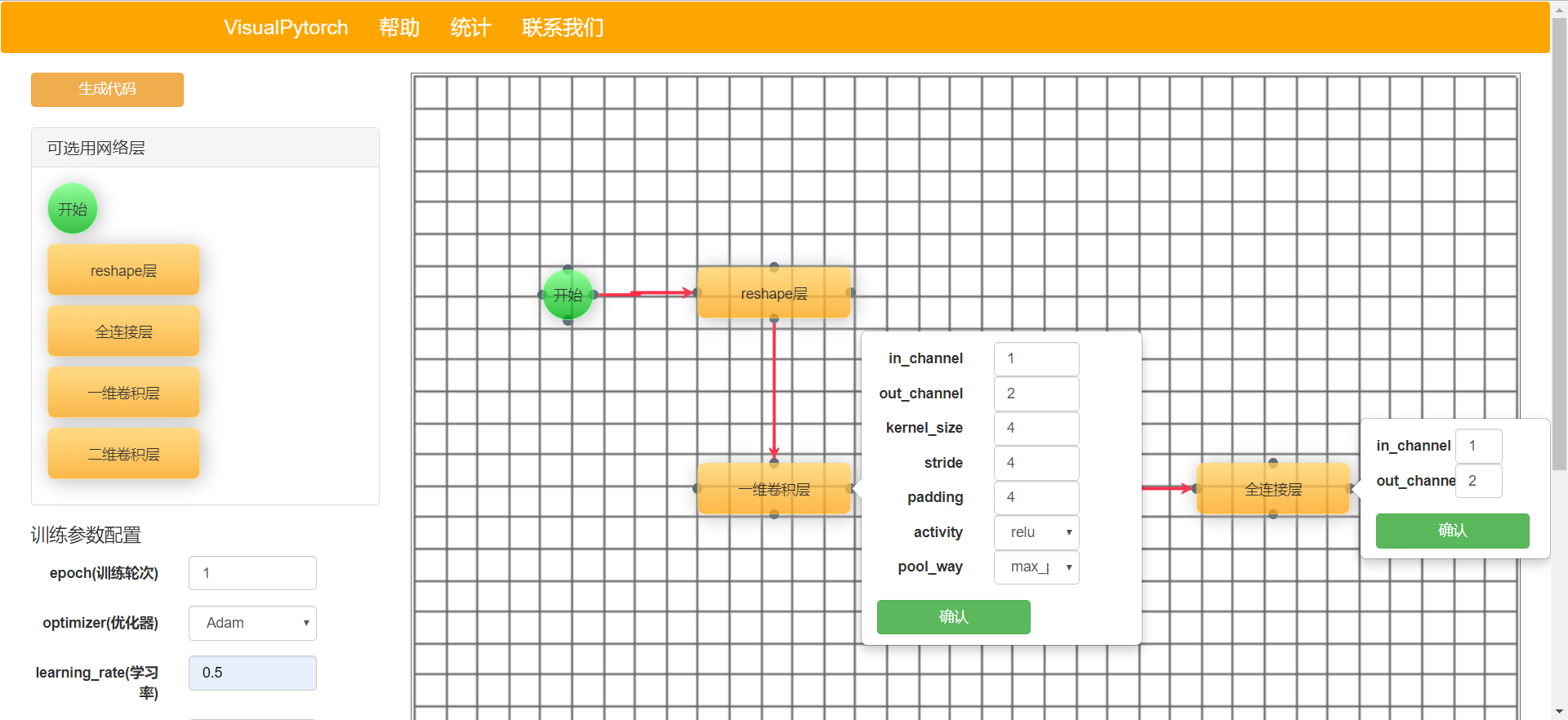
生成代码
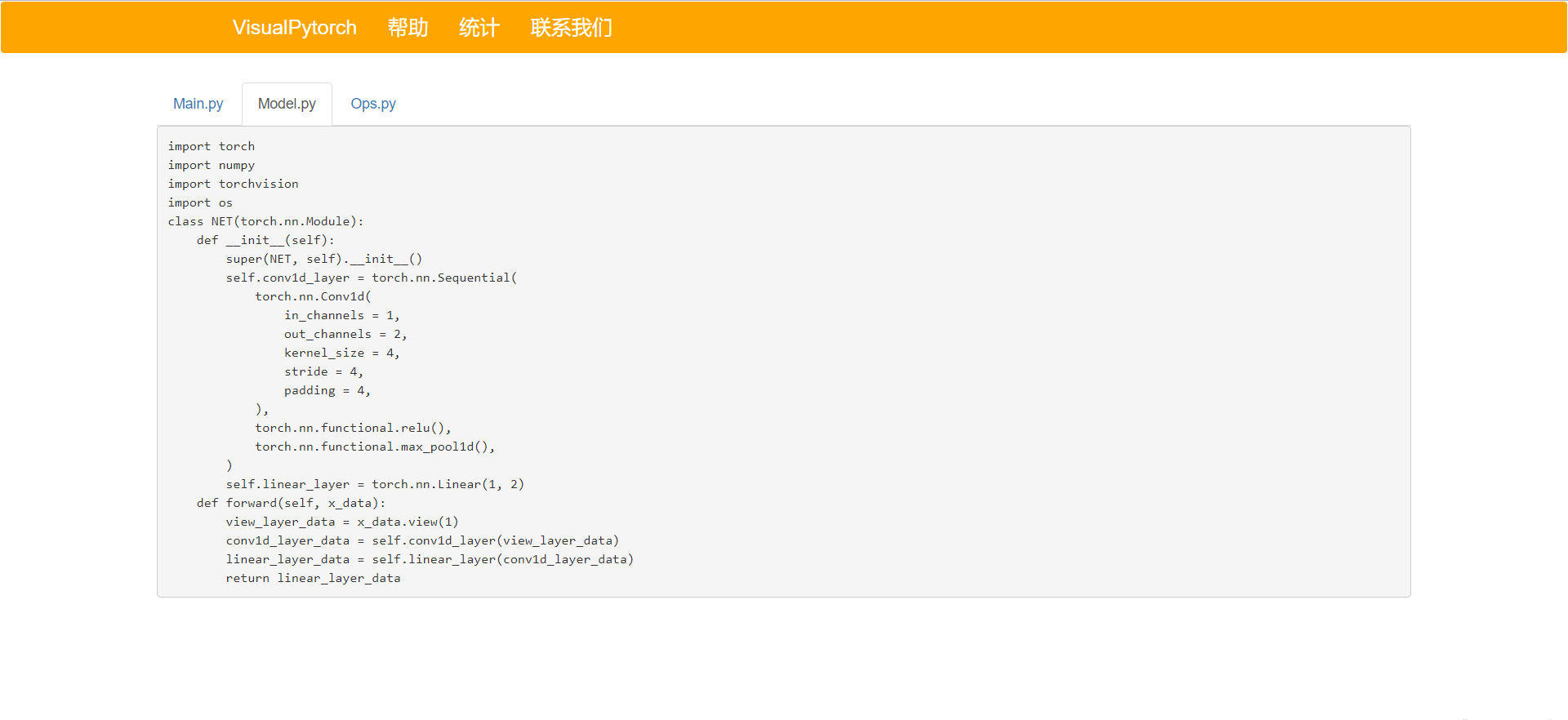
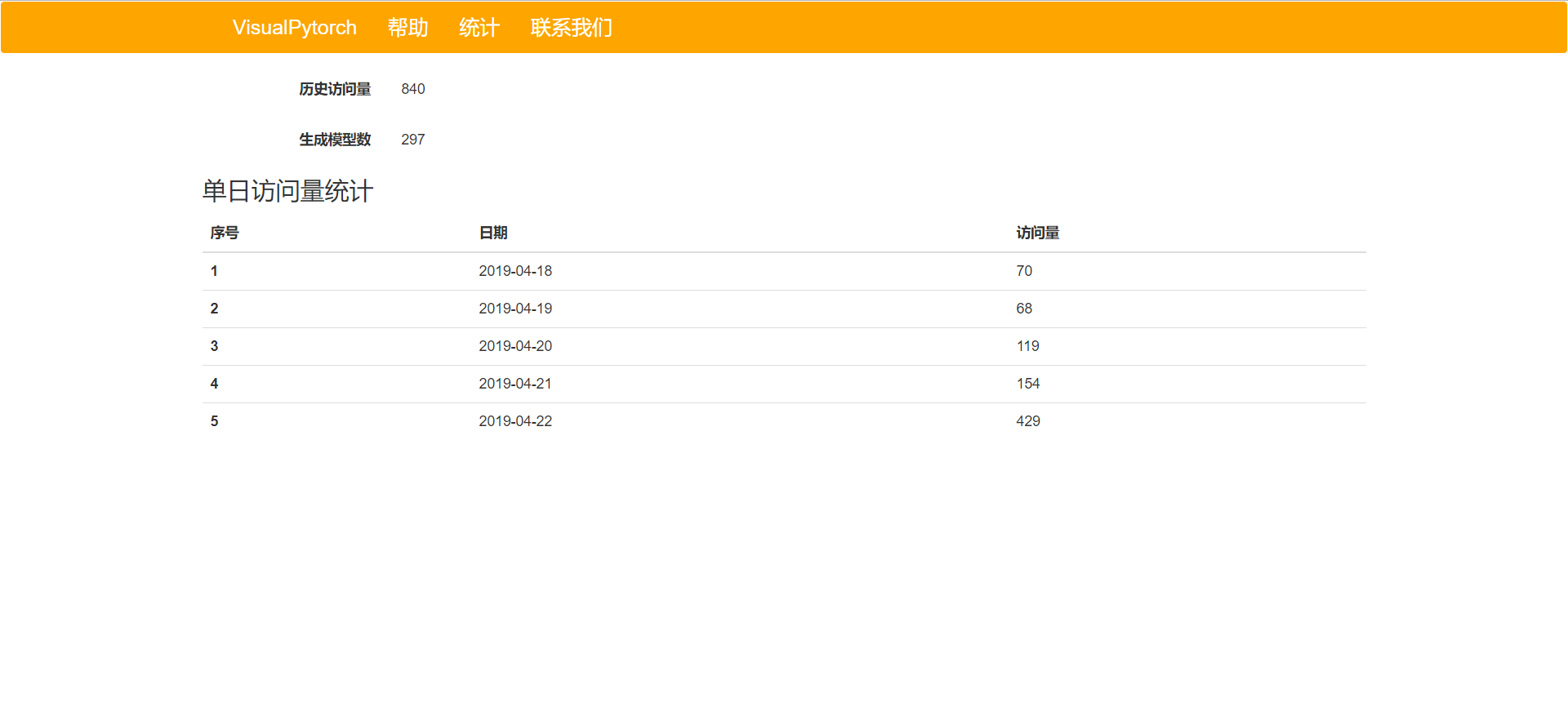
我们的第一代Alpha版本于2019.4.18部署上线,截止到目前已经有了840的访问量和247的生成模型数量,由于还未开放注册/登陆功能,因此还未统计注册用户量。目前的数据量如下:
此外,在我们推广之后,我们也收到了一些用户反馈,这为我们下一阶段需要改进的工作明确了方向,具体反馈内容如下:
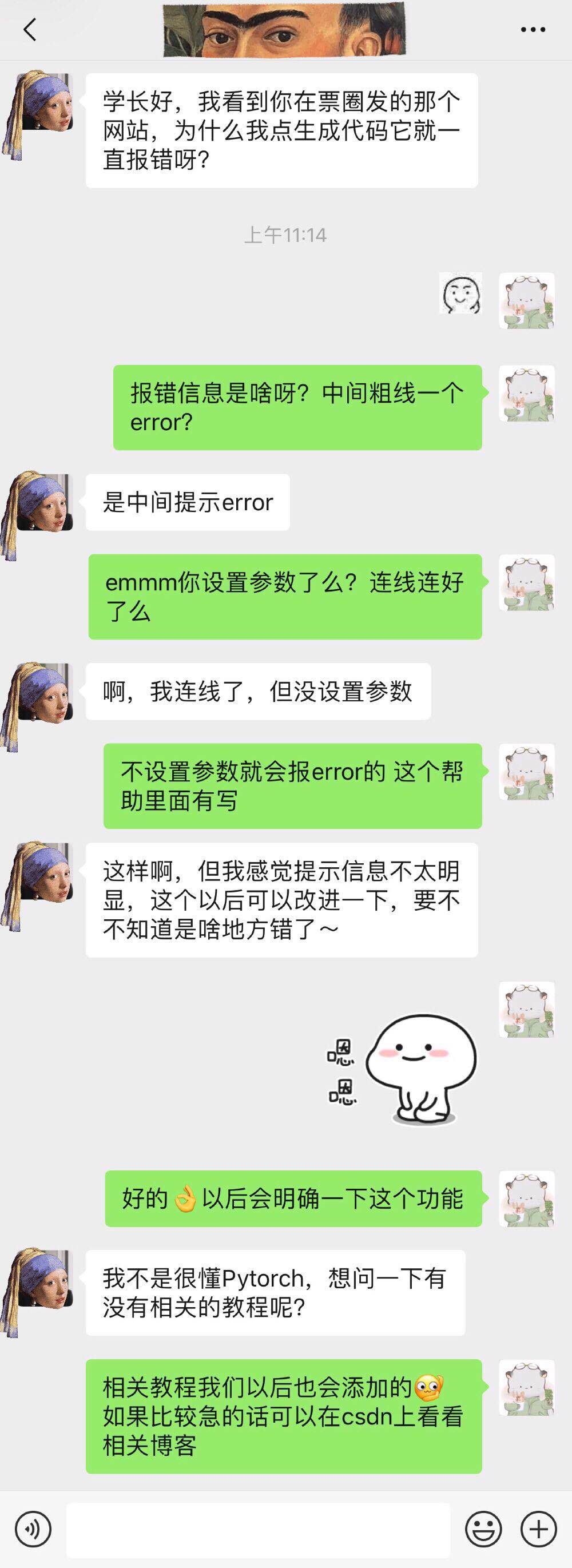 用户反馈1
用户反馈1 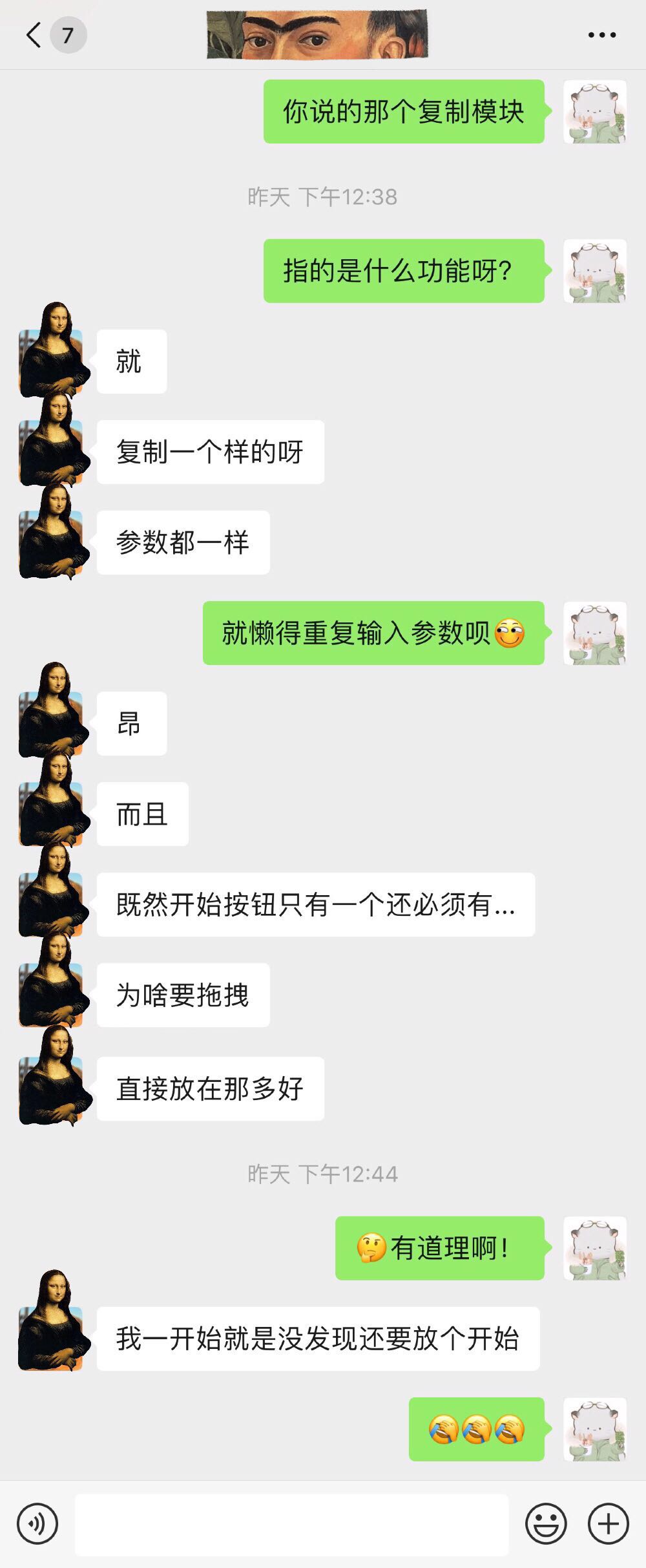 用户反馈2
用户反馈2 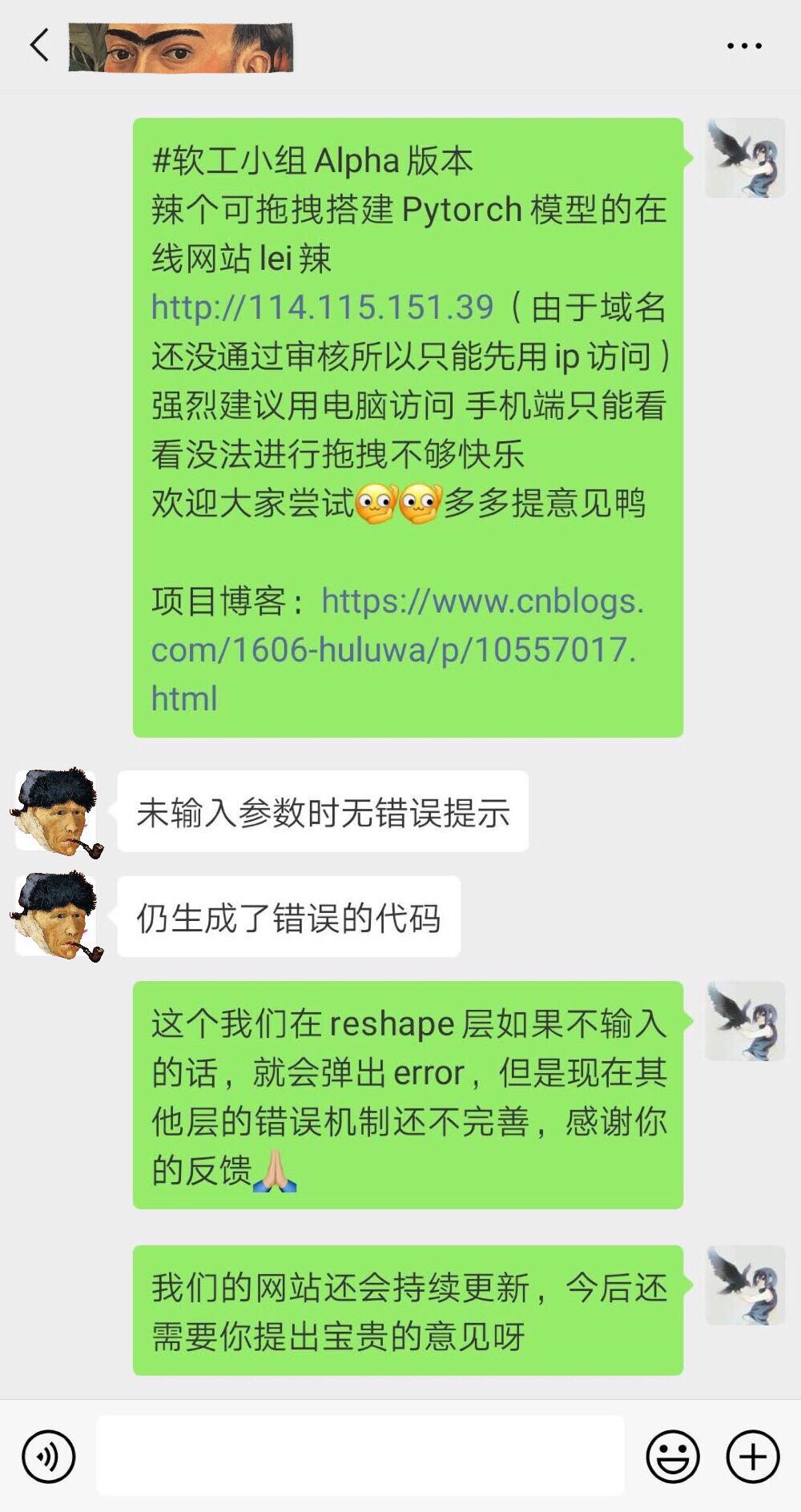 用户反馈3
用户反馈3 3.团队分工
分工协作
由于我们团队本身人数较多,为7个人,高于平均水平,又因为之前我们没有过做完整工程的经验,因此我们选择在标配的基础上,增加一个PM,以便于更好地整体规划和把控项目进度。除了两位PM外,分别由两位同学负责前端的开发、两位同学负责后端的开发,以及一位同学负责测试。平时PM会发布任务,开发组根据日常进度推进开发,如果有突发情况,则团队成员人尽可兵、以尽快解决问题为第一要义。
经验教训
经历了Alpha阶段,主要经验教训有以下两点:
前期产品设计的不足
虽然我们以为已经确定好了产品的各项功能,但真正着手开始开发的时候还是意识到了前期产品设计的不足,许多细节并未敲定,也增加了很大的沟通成本。我们也意识到,前期的产品设计再精细具体也不过分,越精细的设计就会带来越敏捷的开发。
低估了测试的任务量
在第一阶段的开发中,我们想当然的以为,测试的任务并不会太重,重头戏还是在开发上。但接近Alpha阶段的尾声时,才发现测试的任务十分艰巨,一位同学进行测试有些吃力。在下一阶段,我们也会考虑调整人员的分配,衡量好各个部分的人均工作量。
4.项目管理
我们团队选用github来进行项目管理,项目链接为:
PM和测试人员会在github上把相应的工作发布issue,并将其归在负责人的名下,当开发人员完成了任务以后可以在issue下留言,每天晚上PM会检查issue,并关闭已经被完成的issue。项目的issue的链接为:
在时间上,虽然之前听说能够每天早上一起去图书馆,坐在一起面对面开发是效率比较高、效果比较好的开发模式。但由于大三大家都比较忙,也都有自己的安排,有些同学要准备出国、考研等,时间上也不统一,因此我们并未对成员的具体工作时间作要求,只要在DDL之前能够保证质量地完成任务即可。
我们的项目是一个自选项目,还是和深度学习有关,而组内同学并不是所有人都对Pytorch熟悉,因此前期的学习成本比较高,学习周期较长,开发时间相对紧张一些。因此,在Alpha版本中,我们讲精力放在了核心功能的实现上,其余的改善功能,我们将在Beta版本中实现。
5.测试用例
| 测试矩阵 | 功能测试 | 页面测试 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| 测试浏览器 | 测试环境(浏览器版本) | 组件拖拽 | 组件删除 | 组件连线 | 参数输入 | 点击事件(组件、按钮、链接)下拉框选择 | 报错情况 | 生成代码 | 代码的拷贝 | 主页面 | 联系我们页面 | 访问量统计页面 | 代码生成页面 | 页面切换 |
| chrome | 74.0.3724.8 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| 火狐 | 74.0.3724.8 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| ie | 11.706.17134.0 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| edge | 42.17134.1.0 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| 10.4.3457.400 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | |
| UC | 6.2.4094.1 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| Opera | 60.0.3255.56 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| 搜狗 | 8.5.7.29493 | 正常 | 正常 | 正常 | 正常 | 正常 | 在reshape层输入中文报错会占满屏幕,关不掉 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
| 猎豹 | 6.5.115.18480 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 | 正常 |
可以看到,我们的网站在不同的浏览器上的表现还是比较稳定的。此外,为了验证生成的代码是否正确,我们课下的测试方法为生成不同的模型然后覆盖工程中的模型代码,然后去验证是否正确。但为了展示方便,我们找到了一个用我们的组件可以拼接出的github上的模型,然后用它的模型部分代码和我们所生成的代码进行比对,截图如下:




我们找到的github的模型链接为:
6.代码规范及文档
代码规范和所有的文档都保存在github上,在github-doc分支中,文档链接为:

7.需求分析
我们的目标用户有以下几类:
- 典型用户一
| 属性 | 描述 |
|---|---|
| 姓名 | 张XX |
| 身份 | IT行业相关从事者、deep learning初学者 |
| 年龄 | 21岁 |
| 所占比例 | 60% ~ 65% |
| 重要性 | 十分重要,是本网站的核心用户,帮助他们快速入门、练习是本网站的核心功能 |
| 知识层次 | 有一定的计算机专业知识,系统学习过计算机相关课程 |
| 动机/目的 | 利用网站更直观地搭建模型,快速入门deep learning |
| 用户偏好 | 除了可进行模型搭建外,可能还希望有相应的教程、论坛等 |
| …… | …… |
- 典型用户二
| 属性 | 描述 |
|---|---|
| 姓名 | 马XX |
| 身份 | IT行业精英、资深deep learning从事者 |
| 年龄 | 40岁 |
| 所占比例 | 20 ~ 30% |
| 重要性 | 较为重要,可以在论坛中回答初学者的疑问,也会给网站的改进提供意见 |
| 知识层次 | 熟悉计算机专业知识,具有极强的编程能力,精通所从事的领域 |
| 动机/目的 | 出于兴趣逛到网站,为初学者解答疑惑 |
| 用户偏好 | 希望能够更方便地与人交流 |
| …… | …… |
- 典型用户三
| 属性 | 描述 |
|---|---|
| 姓名 | 蒋XX |
| 身份 | 计算机本科学生 || 路人 |
| 年龄 | 18岁 |
| 所占比例 | 10 ~ 15% |
| 重要性 | 一般重要,可以通过网站引起其对deep learning的兴趣,从而转化为核心用户 |
| 知识层次 | 学习过计算机相关课程 || 用过计算机 |
| 动机/目的 | 闲逛论坛/知乎时看到就点了进来看看 |
| 用户偏好 | 需要简单明了的操作指南,美观的UI,有趣的体验等 |
| …… | …… |
其中最为重要的还是deep learning的初学者,而这一批人主要是计算机相关专业在读学生或相关从业人员,考虑到我们身边接触的学生较多,我们以问卷的形式展开用户调查,主要调查用户是否喜欢这种模式的网站,以及对网站的功能还有哪些需求,问卷调查结果如下:
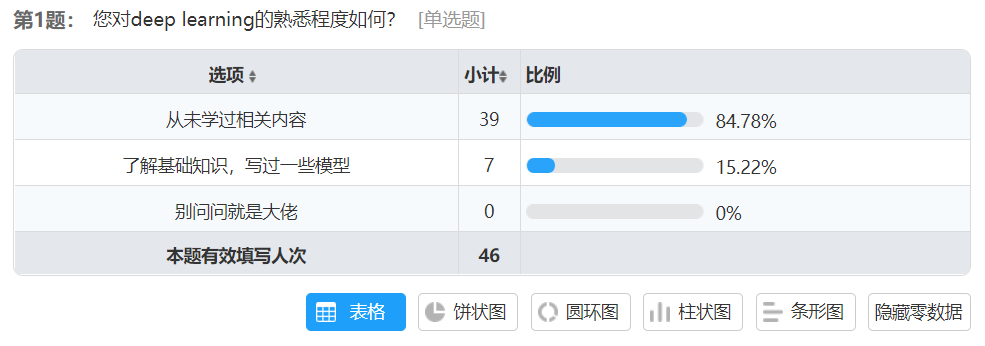

可以看到,这种网站的需求还是比较大的,而且也容易被用户所接受,具体的文件调查结果在我们的github-doc分支中,链接如下:
项目具体信息
1.项目实际进展
在前期,由于团队成员在学习django、pytorch等内容,而这些学习工作一开始没有在github上记录,没有发布issue,所以前期没有什么进度。进入开发阶段以后,由于每天都开例会,且开发人员比较给力,每位同学都能保质保量完成任务,甚至多做一些工作,所以我们的项目推进的也比较顺利。
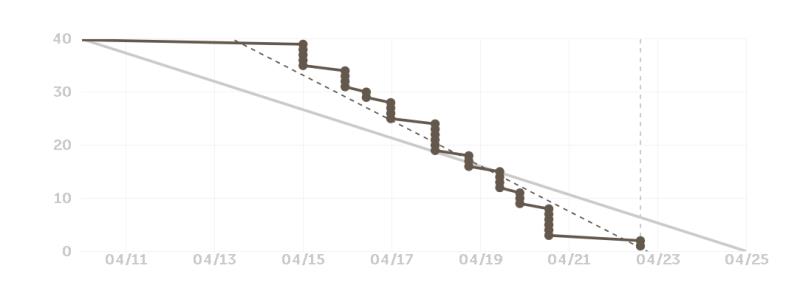
2.发布功能
VisualPytorch的详细介绍请见产品发布说明,链接如下:
3.产品发布
我们产品的IP地址为,同时我们也申请了域名,只是还在审核中,审核通过后我们会第一时间绑定到我们的IP上。
团队成员贡献
| 名字 | 分工 | 团队贡献分 | 具体贡献 |
|---|---|---|---|
| 大娃 | 后端开发 | 50 | (1)后端代码编写(和另一位partern合作)(2)前后端交接文档编写(3)网站帮助文档编写 |
| 二娃 | PM | 51 | (1)scrum meeting博客记录(2)技术规格说明书、【Alpha】发布说明的撰写(3)朋友圈2次推广(4)管理github项目 |
| 三娃 | PM | 52 | (1)设计前端原型图(2)团队介绍、项目选择、功能规格说明书、任务拆解、【Alpha】项目展示等博客的撰写(3)组织召开scrum meeting(4)1次用户需求调查、4次推广(5)管理github项目 |
| 四娃 | 前端开发 | 53 | (1)搭建django的平台,完成了关于神经网络和访问日志的restful api接口(2)完成了可拖拽的组件,实现了网页的基本架构(3)部署网站(4)前端设计文档的撰写 |
| 五娃 | 后端开发 | 48 | (1)后端代码编写(和另一位partern合作)(2)后端设计文档、函数说明的撰写 |
| 六娃 | 测试 | 49 | (1)前端页面、后端代码的测试(2)共发现了15个bug |
| 七弟 | 前端开发 | 47 | (1)部分前端可拖拉部分输入框的开发(2)前端设计文档及部分代码规范文档的撰写 |
总结
网站特色
我们的网站旨在让入门deep learning变得简单、直观、有趣。因为deep learning是一个有趣而又玄学的东西,但如果让初学者因为高门槛、枯燥等因素而被劝退,着实十分可惜。我们的网站就可以让初学者们很直观地进行模型的搭建,就好像搭积木一样,并返回代码,覆盖他已有的模型文件即可进行训练。同时,我们还计划为用户提供讨论交流的平台,进一步帮助用户解决遇到的问题,更顺利地进入deep learning的世界。
Alpha阶段心得
Alpha阶段总的来说,虽然有小的困难,但还是挺顺利的。于我而言,最重要的心得就是对PM在团队中的工作和所担任的角色有了更清晰的认识,PM要做的不仅仅是引导团队前进,还要做团队中各个部分沟通的桥梁,同时也是团队中每个部分之间的调节人员。总而言之,PM的任务就是确保团队这样一个“机器”,每个“部件”之间连接得严丝合缝,能够开足马力前进,而不仅仅是把控方向。
其次,就是认识到了测试的重要性,测试绝非一个轻松、工作量小的工作,就这一点我们也将在Beta阶段中进行调整。
最后,就是所有的想法、沟通等等,最好都要有相应的记录,而不仅仅是在微信群中沟通,有了具体的记录就有了规范的标准,才能够让双方达成共识。否则,很容易出现理解上的分歧。
Beta阶段的计划及对软件工程的建议
在下一阶段,我们将增添更多可拖拽部件,丰富用户可搭建的模型,同时完善生成代码中返回的Main.py和Ops.py。增加注册/登陆功能,并搭建论坛,供用户进行沟通交流。为了保障网站的安全,我们还将增加一些安全防护措施,如验证码、绑定邮箱等等。
软件工程这门课程确实有很深的学问,它不仅仅是写好代码就可以顺利完成项目,还很考验团队协作能力,而团队协作能力是由多种因素所决定的,所以这门课程是对我们综合能力的提升。课程过程中,老师和助教们尽力为我们营造出一种真实的公司开发的氛围,是我们对软件工程的体会加深。但结合我们大三的现状,绝大多数同学面临着出国、考研、保研等需要精力来准备的事情,而敏捷开发本身是一个十分需要全身心投入的东西,而软件工程对于我们来说,确实只是一门课程,我们没办法做到把全部精力都投入到一门课程中去。综上,窃以为课程设置的各个环节有些复杂,也太过耗费精力,如果可以简化一下课程流程,降低课程工作量,与AI、嵌入式的工作量稍微平衡一下,会有更好的体验和口碑。